Studying for the interview
Concepts to study / refresh
(Post in progress)
General
Decorators
Syntactic sugar for a function wrapper.
When writing a wrapper you replace the original function with your wrapper,
losing the docstrings, function name and other metadata in the process.
To avoid this you can use the decorator functools.wraps that simply copies
the metadata over (Link)
misc
@staticmethoddoesn't pass either the class or the instance as first arg, can be called on class.method() or instance.method()@classmethodpasses the class as first arg instead of the instance, can be called on class.method() or instance.method()@propertyused to decorate a getter:@property def OurAtt(self): return self.__OurAtt@<prop>.setterused to decorate a setter:@OurAtt.setter def OurAtt(self, val): if val < 0: self.__OurAtt = 0 elif val > 1000: self.__OurAtt = 1000 else: self.__OurAtt = val(If the
propertydecorator exists the setter has to exist or the property will be read-only):tuples and strings are immutable
- lambda: "single expression anonymous function"
- generator: Link
- monkey patch: (classes are mutable) replacing a class method at runtime
- copying objects: copy.copy or copy.deepcopy
- GC:
- refcounting
- reference cycles
- objects are assigned generations. newer objects are more likely to die. newer objects are dealt with first.
Python3 comments, docs, styling, testing
TBD
Python3 cool stuff
Advanced unpacking
>>> a, b, *rest = range(4)
>>> a
0
>>> b
1
>>> rest
[2, 3]
rest can go anywhere (a, *rest, b; *rest, a, b)
Keyword only arguments
def f(a, b, *, option=True):
pass
You can't call f(a, b, True) anymore, you have to explicitly set the value
(f(a, b, option=True))
asyncio
- Event loop manages and distributes execution of tasks
- Coroutines
similar to generators, returns value and program flow on
await - Futures objects that represent the result of a task that may or may not have been executed
Coroutines contain yield points where we define possible points where a context switch can happen if other tasks are pending, but will not if no other task is pending.
A context switch in asyncio represents the event loop yielding the flow of control from one coroutine to the next.
Caching 1
Optimistic Caching
Always reply with the memorized value, check if the TTL was exceeded later. This can return a non-answer (until the cache is populated)
Total latency
The latency for any given function will be the defined latency for the function plus the maximum latency of all of its (recursive) dependencies.
Caching 2
Notes:
Memcache has limits (1MB value size, serializing keys/values is cpu intensive);
redis doesn't have these limitations (512MB max value size, keys and values can be binary data)
Tiered cache: "Can't hold many items" (max open file limits)
Max practical limit in ext4 is ~1 million
To avoid all clients hitting the DB at the same time when the cache expires
- Use a task queue to dedup requests
- Randomize refresh times
- Coordinate between workers
MFU key expiring: Eventually it'll expire and all workers will start querying the slower cache tiers (maybe DoSing them). A good way to solve this is having a background process actively refreshing the MFU keys.
mmap
Map a file directly to program space; this is useful to avoid doing read() all the time and avoids copying the file to userspace.
dogpile effect
Self DoS when a MFU key expires. A possible solution is to only have the first process requesting the expired value perform the re-computation and have the rest serve stale data.
Cython
Faster code via static typing
Priority queue heap
Insert / RemoveMax = O(log n)
Properties:
Heap-order property (for a “MinHeap”)
For every node X key(parent(X)) ≤ key(X)
minimum key always at root
- Insert and deleteMin must maintain
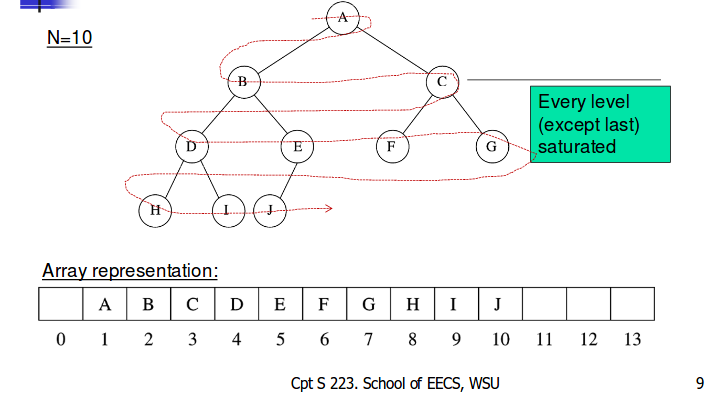
heap ordering in array
MapReduce
Tornado
ZeroMQ
PostgreSQL
bussiness stuff
open app -> requests ad to exchange -> auction -> bidders (jampp)
arch
┌─> Logger -> PostgreSQL Cluster
ELB -> bidder (60-230 inst) ─┼─> Cache (L3, Networked)
├─> User segments -> Presto
└─> ML stuff
bidders
Kinesis -> Lambda -> Kinesis -> S3 -> PrestoDB
│ (Firehose) │ ^
│ │ │
v └──> Spark
DynamoDB
Latency
The bidder runs on Linux (unknown), each node hosts an nginx instance which does reverse proxying to gunicorn.
Kernel:
- Consider changing the value of the kernel's clock freq (
CONFIG_HZ) - Hardware offload for TCP checksum?
- Is the TCP stack tuned for latency? BBR?
- Can MTU be increased?
- Swap?
- Compressed swap? zswap?
- zram?
Userspace:
- Is nginx necessary?
- The data travels Kernel ─> Nginx ─> Kernel ─> gunicorn
- Could be Kernel ─> gunicorn
- If necessary, can
sendfile,tcp_nodelay,tcp_nopushhelp? - is config optimal?
- Why gunicorn? Why not uwsgi?
- is cpu affinity used?
General:
- What's the standard response size? And headers?
- libuv for tornado? See here
Benchmarking:
- Is it done? How? can traffic be cloned to be replayed back later? (see tcpreplay)
Misc data:
- The typical latency of a 1 Gbit/s network is about 200 us, while the latency with a Unix domain socket can be as low as 30 us. source
- On Linux, some people can achieve better latencies by playing with process placement (taskset), cgroups, real-time priorities (chrt), NUMA configuration (numactl), or by using a low-latency kernel.